Публикации
Человечество неправильно обучает ИИ
Исследование: человечество неправильно обучает ИИ — большинство моделей не работают в реальном мире
К такому выводу пришли 40 исследователей из Google. Почему за границами лабораторий модели машинного обучения не оправдывают себя — в конспекте материала MIT Technology Review.
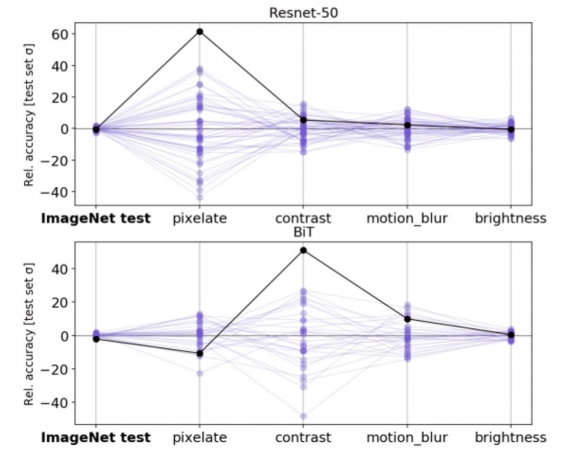
Результаты стресс-теста 50 различных моделей машинного обучения при одинаковых условиях
Часто модели машинного обучения нежизнеспособны из-за того, что данные, на которых их обучали, не соответствуют с данными в реальности. К примеру, исследователи обучают ИИ распознавать признаки болезни по качественным медицинским снимкам, но в реальных клинических условиях они сделаны наскоро и дешёвой камерой.
Но это не единственная проблема. Группа из 40 исследователей из семи различных команд Google выявила ещё одну — недоспецификацию.
Представим типичный сценарий: сначала модель обучают на множестве примеров, после тестируют на новых данных — и спустя несколько этапов её можно применять на практике.
Однако исследователи считают, что способ слишком грубый. В таком обучении не учитываются:
· Случайные значения, которые могла задать нейросеть ещё до начала обучения.
· Способ выбора и демонстрации данных.
· Количество тестов.
При одинаковых условиях можно создать разные модели — и все они будут немного отличаться, если не учесть детали. Эти незначительные, часто случайные различия игнорируются, но в реальности могут сильно влиять на итоговый результат. Поэтому невозможно предсказать, будет ли тестируемая модель жизнеспособна, думают исследователи Google.
И проблема не похожа на несоответствие обучающих данных с реальными. Недоспецификация — это когда даже при удачном тестировании модели в реальности ИИ может оказаться нерабочим.
Исследователи проверили гипотезу: они взяли несколько моделей и провели их через одинаковые процессы машинного обучения. После запустили несколько стресс-тестов, чтобы быстро проверить различия в производительности.
К примеру, они взяли 50 моделей и обучили их распознавать изображения. Для этого исследователи использовали базу данных ImageNet. Единственным отличием в моделях были случайные значения, присвоенные нейросети на старте.
В тестировании использовали ImageNet-C — набор картинок из ImageNet, но сжатых до нескольких пикселей и с изменёнными яркостью и контрастностью. Также взяли изображения ObjectNet — повседневные объекты под непривычными углами и со сложным фоном: перевёрнутые чайники и стулья, висящие на крючках футболки.
Часть моделей лучше распознавала пиксельные картинки, часть — предметы. В итоге они показали похожий результат, но с разной производительностью.
После сделали тесты по тому же принципу, но уже с медицинскими данными, результат тот же — модели, которые должны были быть одинаково точными, работали по-разному при тестировании с реальными данными.
Исследователи указывают, что нужно делать гораздо больше тестов, чтобы ИИ был жизнеспособнее в реальных условиях. Но это непросто: для текущего эксперимента в стресс-тестах использовали данные из реального мира или данные, имитирующие его. Это не всегда доступно.
Порой результаты противоречат друг другу: некоторые модели, которые хорошо распознавали пиксельные изображения, плохо распознавали контрастные изображения. Это показывает, что сложно обучить нейросеть, которая успешно пройдёт сразу несколько подобных тестов.
Что с этим делать
Одно из решений — разработать дополнительный этап обучения и тестирования, в котором параллельно выпускают сразу несколько моделей. Эти модели снова тестируют на реальных примерах, а после выбирают лучшую для конкретной задачи.
Но исследователь машинного обучения в ETH Zurich Янник Килчер говорит, что это слишком сложно для обычных исследователей и бизнеса — подобные разработки могут позволить себе корпорации вроде Google.
Автор исследования Алекс Д'Амур пока не понимает, как решить эту проблему, нужно изучить всё детальнее: «Часто мы только в самом конце узнаём, что требуется от модели обучения, когда она оказалась неудачной в реальном мире».